Introducing $\texttt{minicons}$: Running large scale behavioral analyses on transformer language models
Premise
Assume that just like any other day in the Natural Language Processing (NLP) community, you read a tweet about this fancy new transformer (Vaswani et al. 2017) language model that has recently come out and is touted to solve many NLP tasks!
Let’s call it 🤖.
Now lets say that you are an NLP researcher, and just like me, you are interested in understanding and evaluating models like 🤖.
Fortunately for you, due to the hard work put in by Huggingface, 🤖 has been made public and now appears on its model hub (for the purposes of this post, let’s assume that 🤖 = distilgpt2).
Assuming for the purposes of this post, you are interested in morpho-syntax,1 you might ask the question:
How well does 🤖 learn subject-verb agreement?
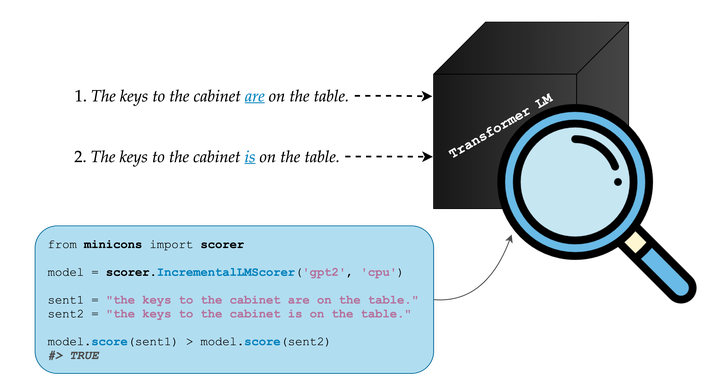
If you were to conduct an experiment to answer this question in the context of native English speakers, you’d present several human subjects pairs of sentences that look like (1) and (2) and ask them to rate which one is more acceptable:
- the keys to the cabinet are on the table.
- the keys to the cabinet is on the table.
In the above examples, knowledge about subject-verb agreement is tested by checking if the agent (human, our model 🤖, etc.) rates (1) as more acceptable than (2), since the number of the verb (is vs. are) has to agree with the subject, keys. Such an experiment is common to the psycholinguistic domain, where participants are presented with stimuli that are targeted to probe for a particular information.
But how does one perform the same experiment with 🤖?
Since it is a language model, 🤖 assigns probabilities to words in a sequence.
Maintaining the assumption that 🤖 is the the same as distilgpt2, it estimates the probability of a word \(w_i\) in the sequence \(s = w_1, w_2, ..., w_{n-1}\) as \(p(w_i \mid w_1, ..., w_{i-1})\).
To calculate the probability of (is/are) in our example sentences, the model computes the expression \(p(\textit{is } \text{or} \textit{ are } \mid \textit{ the, keys, to, the, cabinet)}\).
One could treat this conditional probability as a measure of how plausible the given phrase (the keys to the cabinet is or the keys to the cabinet are) is w.r.t. to the model’s trained parameters, as was done by Linzen, Dupoux, and Goldberg (2016), and subsequent works.
Therefore, a good language model of English—just like humans—will tell you that (1) is more plausible than (2), i.e. \(p(\textit{are} \mid \textit{the, keys, to, the, cabinet)} > p(\textit{is } \mid \textit{ the, keys, to, the, cabinet)}\).
Enter \(\texttt{minicons}\):
\(\texttt{minicons}\) is a python library that lets you conduct experiments similar to the one sketched out above on a large scale.
It automates the probability computations of transformer LMs that are accessible through the transformers package by HuggingFace, so that you—the researcher—can instead spend most of your time and effort in carefully designing experiments and stimuli that target aspects of linguistic knowledge that the model should ideally encode.
\(\texttt{minicons}\) is on pypi, and can be installed using the following terminal command:
pip install miniconsTo score sentences or phrases, you’ll need the scorer module from the library. In the snippet below, I have also loaded other packages that will help demonstrate how one can rapidly run behavioral experiments using \(\texttt{minicons}\).
from minicons import scorer
import json
import statistics
from torch.utils.data import DataLoaderSticking to the subject-verb agreement task, one could collect/construct pairs of sentences that differ in their verb/auxiliary verb depending on the subject, such as examples (1) and (2). For simplicity, let’s use the one that appears in a recent dataset/paper called BLiMP (Warstadt et al. 2020).
The BLiMP dataset consists of 67 different stimuli types (1000 pairs of sentences per stimuli-type), each targeted to evaluate a unique linguistic phenomenon based on one of 12 different paradigms (see Table 1 in Warstadt et al. (2020) for a summary of these paradigms), totaling to 67,000 pairs of sentence stimuli.
One stimuli type relevant to the subject-verb agreement paradigm that you might be interested in is contained in a file called distractor_agreement_relational_noun.jsonl, made publicly available on the lead author’s github.
The stimuli contained in this particular subset only cover one aspect of subject-verb agreement knowledge — one requiring a verb’s agreement with the number of a noun that is held constant across a given pair of sentences (see Table 4 in the same paper to explore other ways of evaluating subject-verb agreement).
Let’s now load the stimuli from the file:
stimuli = []
with open("distractor_agreement_relational_noun.jsonl", "r") as f:
for line in f:
row = json.loads(line)
stimuli.append([row['one_prefix_prefix'] + " " + row['one_prefix_word_good'], row['one_prefix_prefix'] + " " + row['one_prefix_word_bad']])
# Let's take a look at some of the stimuli
for pair in stimuli[:5]:
print(f"{pair[0]} vs. {pair[1]}")## A niece of most senators hasn't vs. A niece of most senators haven't
## The sketch of those trucks hasn't vs. The sketch of those trucks haven't
## A newspaper article about the Borgias has vs. A newspaper article about the Borgias have
## The niece of most guests has vs. The niece of most guests have
## A sketch of lights doesn't vs. A sketch of lights don'tNotice that we only need the left context of the target words (is vs are in the running example), since our model, 🤖, is an incremental LM, i.e., it estimates the probability of a word by conditioning on its left context.
To load our model, \(\texttt{minicons.scorer}\) provides the IncrementalLMScorer class to instantiate any Incremental language model that is accessible through huggingface’s transformers library.
For this post, I’ve loaded it onto my cpu but one could also use a cuda device if it is available to them.
model = scorer.IncrementalLMScorer('distilgpt2', 'cpu')## Using pad_token, but it is not set yet.Let’s also instantiate a dataloader so that we can run computations in batches as opposed to one at a time. This enables fast and efficient computation, and forms the core philosophy of \(\texttt{minicons}\).
stimuli_dl = DataLoader(stimuli, batch_size = 100)Let’s now compute 🤖‘s scores on the 1000 sentence pairs in our evaluation stimuli.
This is done by invoking the .score() method of our instantiated model.
By default, it computes the log probabilities of the batch of input sentences, divided by their length (using torch.mean()), but also allows you to specify other aggregation functions, such as sum, geometric mean, or any other custom function that accepts a tensor of log-probabilities and returns a scalar for every row. To keep things simple, let’s call our outputs ’scores’ \((s)\).
results = []
for batch in stimuli_dl:
good, bad = batch
good_score = model.score(good)
bad_score = model.score(bad)
results.extend(zip(good_score, bad_score))This gives us a results list containing (good_score, bad_score) tuples, each of which contain scores of the good vs. the bad inputs.
It’s typical to synthesize the results of such an experiment using an aggregated metric, to give us a summarized view of the model’s performance on the task.
For instance, one could compute the accuracy \(\mathcal{A}\), by comparing the mean log probabilities, or scores, of “good” and “bad” instances in the evaluation dataset:
\[ \begin{align} \mathcal{A} = \frac{1}{n}\sum_{i = 1}^n\mathbb{1}\{s(\text{good})~>~s(\text{bad})\}_i, \tag{1} \end{align} \]
where \(\mathbb{1}\{\}_i\) is an indicator function that accepts a condition and outputs 1 if the condition is met for the given instance (\(i\)), and 0 otherwise. This is straightforward to implement in python:
def accuracy(data):
return statistics.mean([g > b for g, b in data])
# Computing accuracy of our model:
print(f"The accuracy of the model is {round(accuracy(results)*100, 2)}%")## The accuracy of the model is 81.8%How does this compare to other models, or even humans? Let’s take a look at the paper’s results:
| 5-gram | LSTM | TXL | GPT2 | Human | 🤖 (distilgpt2) |
|---|---|---|---|---|---|
| 24.00% | 76.00% | 77.00% | 83.00% | 81.00% | 81.80% |
Surprisingly, our model 🤖 ends up performing better than humans, and almost similar to GPT2 (which incidentally 🤖 is actually based on)! The observation that the model is able to out-perform humans should be taken with extreme caution. One potential reason could be purely statistical — the model is optimized to predict the statistical properties of word sequences, and it could have performed slightly better than humans if it has seen certain contiguous sequences (perhaps n-gram patterns of certain words) in its training corpus. If this is true then the model should have near-perfect memory of those sequence patterns that it has seen during training. Another potential reason could be the noise in human judgment – the authors only selected 100 sentences from each of the 67 different phenomena for their crowdsourcing experiment so not all sentences were annotated by humans. Overall, the original paper (Warstadt et al. 2020) also reports a greater differential between humans and models on more challenging grammar tasks, favoring the humans. This suggests that our language models can acquire basic facts about the English language, but still have a long way to go in order to perfectly represent a diverse set of linguistic phenomena. For a detailed discussion on models vs. humans on these task, I urge you to read the original paper.
What else can be done using \(\texttt{minicons}\)?
I have only demonstrated one major application of \(\texttt{minicons}\) — the ability to rapidly run relative acceptability judgments on vast amount of linguistic data. The library also supports a whole host of other operations. Some include:
- evaluating on masked language models
- extracting hidden state representation at any layer of a given model
- extracting and comparing the output distribution of the model on a given prompt
- “priming” of language models where the model is conditioned on a given text and is evaluated on multiple continuations. A primitive version of this was used in my paper (Misra, Ettinger, and Rayz 2020)
- exploring the outputs of models pre-trained to perform specific NLP tasks such as natural language inference, etc
I also plan to add support for many more evaluation techniques as I make progress in my research, but I invite anyone to try and contribute to this library, especially since this is my very first time! Some potential ways of doing so could be:
- writing better documentation, perhaps making a website to host it all
- writing tutorials to showcase the usefulness of the library
- adding new functionality
So feel free to create PRs/Issues and I will be happy to collaborate on them with you!
Closing thoughts
In this post I demonstrated one crucial application of my latest python library: \(\texttt{minicons}\), by applying it on a toy evaluation setting based on basic English grammar, for a semi-fictitious model called 🤖.
Though simple, the computations supported by the library facilitate running of large-scale behavioral analyses of transformer-based language models through simple interaction with huggingface’s transformer library and pytorch.
The source code for this post (in RMarkdown, with python code supported through reticulate) can be found here.
Acknowledgments
Thanks to Hemanth Devarapalli for inspiring me to convert my code into a library and Ananya Sheth for suggesting fine-grained edits to this post.
References
Linzen, Tal, Emmanuel Dupoux, and Yoav Goldberg. 2016. “Assessing the Ability of Lstms to Learn Syntax-Sensitive Dependencies.” Transactions of the Association for Computational Linguistics 4: 521–35.
Misra, Kanishka, Allyson Ettinger, and Julia Rayz. 2020. “Exploring BERT’s Sensitivity to Lexical Cues Using Tests from Semantic Priming.” In Findings of the Association for Computational Linguistics: EMNLP 2020, 4625–35. Online: Association for Computational Linguistics. https://www.aclweb.org/anthology/2020.findings-emnlp.415.
Vaswani, Ashish, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. “Attention is All you Need.” In NeurIPS 2017, 5998–6008.
Warstadt, Alex, Alicia Parrish, Haokun Liu, Anhad Mohananey, Wei Peng, Sheng-Fu Wang, and Samuel R. Bowman. 2020. “BLiMP: The Benchmark of Linguistic Minimal Pairs for English.” Transactions of the Association for Computational Linguistics 8: 377–92. https://doi.org/10.1162/tacl\_a\_00321.
the study of the internal structure of words and how they combine to form a sentence or a phrase.↩︎
Kanishka Misra
Assistant Professor of Linguistics and Harrington Fellow at UT-Austin
I do computational linguistics and cognitive science.