Experimental Contexts Can Facilitate Robust Semantic Property Inference in Language Models, but Inconsistently
Abstract
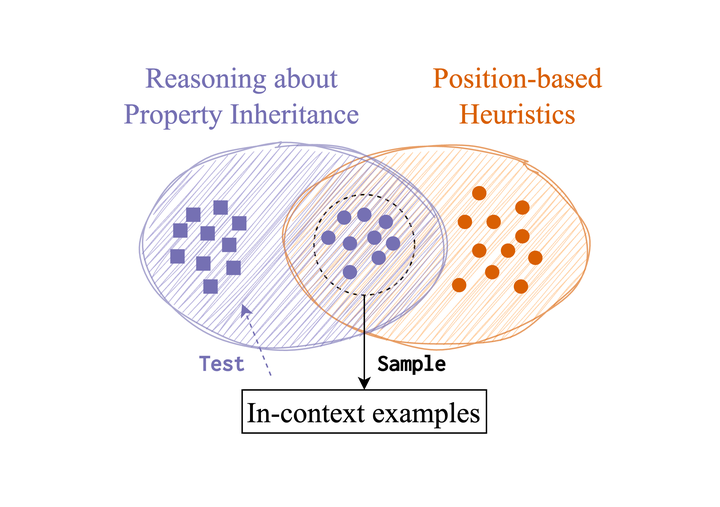
Recent zero-shot evaluations have highlighted important limitations in the abilities of language models (LMs) to perform meaning extraction. However, it is now well known that LMs can demonstrate radical improvements in the presence of experimental contexts such as in-context examples and instructions. How well does this translate to previously studied meaning-sensitive tasks? We present a case-study on the extent to which experimental contexts can improve LMs’ robustness in performing property inheritance—predicting semantic properties of novel concepts, a task that they have been previously shown to fail on. Upon carefully controlling the nature of the in-context examples and the instructions, our work reveals that they can indeed lead to non-trivial property inheritance behavior in LMs. However, this ability is inconsistent: with a minimal reformulation of the task, some LMs were found to pick up on shallow, non-semantic heuristics from their inputs, suggesting that the computational principles of semantic property inference are yet to be mastered by LMs.
Kanishka Misra
Assistant Professor of Linguistics and Harrington Fellow at UT-Austin
I am an Assistant Professor of Linguistics at UT Austin!